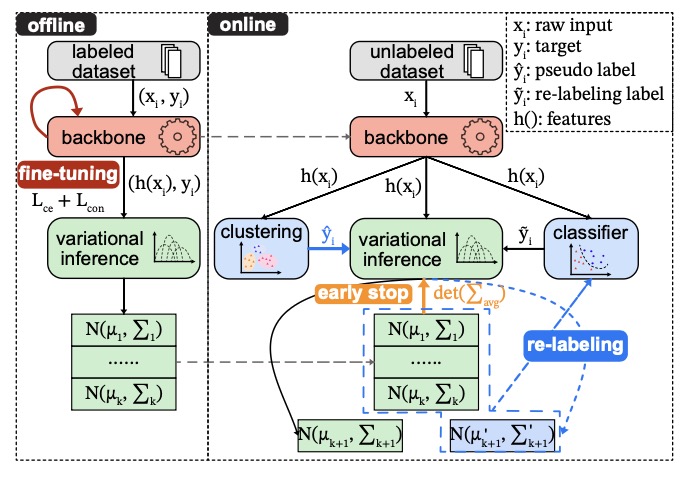
Continual Generalized Category Discovery (C-GCD) faces a critical challenge: incrementally learning new classes from unlabeled data streams while preserving knowledge of old classes. Existing methods struggle with catastrophic forgetting, especially when unlabeled data mixes known and novel categories. We address this by analyzing C-GCD’s forgetting dynamics through a Bayesian lens, revealing that covariance misalignment between old and new classes drives performance degradation. Building on this insight, we propose Variational Bayes C-GCD (VB-CGCD), a novel framework that integrates variational inference with covariance-aware nearest-class-mean classification. VB-CGCD adaptively aligns class distributions while suppressing pseudo-label noise via stochastic variational updates. Experiments show VB-CGCD surpasses prior art by +15.21% with the overall accuracy in the final session on standard benchmarks. We also introduce a new challenging benchmark with only 10% labeled data and extended online phases—VB-CGCD achieves a 67.86% final accuracy, significantly higher than state-of-the-art (38.55%), demonstrating its robust applicability across diverse scenarios.
@inproceedings{pmlr-v267-dai25a,title={Continual Generalized Category Discovery: Learning and Forgetting from a {B}ayesian Perspective},author={Dai, Hao and Chauhan, Jagmohan},booktitle={Proceedings of the 42nd International Conference on Machine Learning},pages={11884--11903},year={2025},editor={Singh, Aarti and Fazel, Maryam and Hsu, Daniel and Lacoste-Julien, Simon and Berkenkamp, Felix and Maharaj, Tegan and Wagstaff, Kiri and Zhu, Jerry},volume={267},series={Proceedings of Machine Learning Research},month={13--19 Jul},publisher={PMLR},url={https://proceedings.mlr.press/v267/dai25a.html},}
2024
OSDN
Open Set Dandelion Network for IoT Intrusion Detection
Jiashu
Wu, Hao
Dai, Kenneth B.
Kent, and
3 more authors
As Internet of Things devices become widely used in the real-world, it is crucial to protect them from malicious intrusions. However, the data scarcity of IoT limits the applicability of traditional intrusion detection methods, which are highly data-dependent. To address this, in this article, we propose the Open-Set Dandelion Network (OSDN) based on unsupervised heterogeneous domain adaptation in an open-set manner. The OSDN model performs intrusion knowledge transfer from the knowledge-rich source network intrusion domain to facilitate more accurate intrusion detection for the data-scarce target IoT intrusion domain. Under the open-set setting, it can also detect newly-emerged target domain intrusions that are not observed in the source domain. To achieve this, the OSDN model forms the source domain into a dandelion-like feature space in which each intrusion category is compactly grouped and different intrusion categories are separated, i.e., simultaneously emphasising inter-category separability and intra-category compactness. The dandelion-based target membership mechanism then forms the target dandelion. Then, the dandelion angular separation mechanism achieves better inter-category separability, and the dandelion embedding alignment mechanism further aligns both dandelions in a finer manner. To promote intra-category compactness, the discriminating sampled dandelion mechanism is used. Assisted by the intrusion classifier trained using both known and generated unknown intrusion knowledge, a semantic dandelion correction mechanism emphasises easily-confused categories and guides better inter-category separability. Holistically, these mechanisms form the OSDN model that effectively performs intrusion knowledge transfer to benefit IoT intrusion detection. Comprehensive experiments on several intrusion datasets verify the effectiveness of the OSDN model, outperforming three state-of-the-art baseline methods by 16.9%. The contribution of each OSDN constituting component, the stability and the efficiency of the OSDN model are also verified.
@article{10.1145/3639822,author={Wu, Jiashu and Dai, Hao and Kent, Kenneth B. and Yen, Jerome and Xu, Chengzhong and Wang, Yang},title={Open Set Dandelion Network for IoT Intrusion Detection},year={2024},volume={24},number={1},doi={10.1145/3639822},journal={ACM Trans. Internet Technol.},pages={26},impactfactor={5.3},erank={SCI Q1},crank={CCF-B},dimensions={true}}
2023
NOAC
Neighborhood-Oriented Decentralized Learning Communication in Multi-Agent System
Hao
Dai, Jiashu
Wu, André
Brinkmann, and
1 more author
In Artificial Neural Networks and Machine Learning - ICANN, 13–19 jul 2023
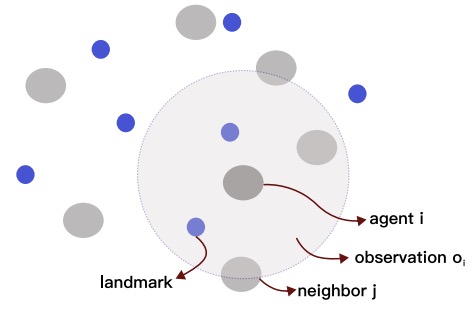
Partial observations are one of the critical obstacles in multi-agent systems (MAS). The Centralized Training Decentralized Execution (CTDE) paradigm has been widely studied to integrate global observations into the training process. However, the traditional CTDE paradigm suffers from local observations during the execution phase, and numerous efforts have been made to study the communication efficiency among agents to promote cognitive consistency and better cooperation. Furthermore, training still operates in a centralized manner, requiring agents to communicate with each other in a broadcast fashion. As a consequence, this centralized broadcast-based training process is not feasible when being applied to more complex scenarios. To address this issue, in this paper we propose a neighborhood-based learning approach to enable agents to perform training and execution in a decentralized manner based on information received from their neighboring nodes. In particular, we design a novel encoder network and propose a two-stage decision model to improve the performance of this decentralized training. To evaluate the method, we further implement a prototype and perform a series of simulation-based experiments to demonstrate the effectiveness of our method in multi-agent cooperation compared to selected existing multi-agent methods to achieve the best rewards and drastically reduce data transmission during training.
@inproceedings{10.1007/978-3-031-44213-1_41,author={Dai, Hao and Wu, Jiashu and Brinkmann, Andr{\'e} and Wang, Yang},editor={Iliadis, Lazaros and Papaleonidas, Antonios and Angelov, Plamen and Jayne, Chrisina},title={Neighborhood-Oriented Decentralized Learning Communication in Multi-Agent System},booktitle={Artificial Neural Networks and Machine Learning - ICANN},year={2023},publisher={Springer Nature Switzerland},address={Cham},pages={490--502},isbn={978-3-031-44213-1},erank={Core B},crank={CCF-C},}
OTSharing
Cost-Efficient Sharing Algorithms for DNN Model Serving in Mobile Edge Networks
Hao
Dai, Jiashu
Wu, Yang
Wang, and
3 more authors
IEEE Transactions on Services Computing, 13–19 jul 2023
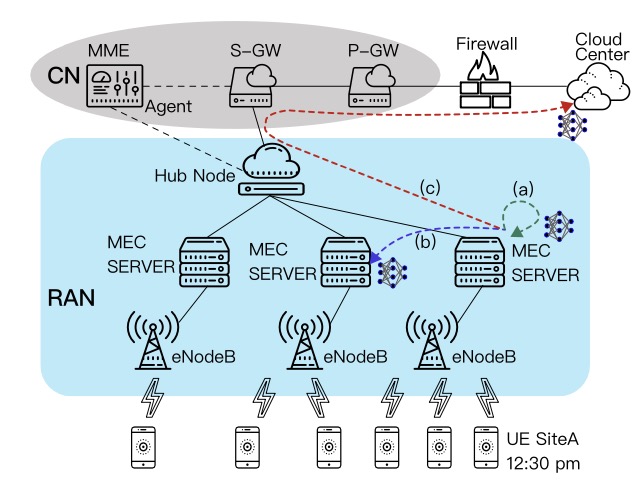
With the fast growth of mobile edge computing (MEC), the deep neural network (DNN) has gained more opportunities in application to various mobile services. Given the tremendous number of learning parameters and large model size, the DNN model is often trained in cloud center and then dispatched to end devices for inference via edge network. Therefore, maximizing the cost-efficiency of learned model dispatch in the edge network would be a critical problem for the model serving in various application contexts. To reach this goal, in this article we focus mainly on reducing the total model dispatch cost in the edge network while maintaining the efficiency of the model inference. We first study this problem in its off-line form as a baseline where a sequence of n requests can be pre-defined in advance and exploit dynamic programming techniques to obtain a fast optimal algorithm in time complexity of O(m2n) under a semi-homogeneous cost model in a m -sized network. Then, we design and implement a 2.5-competitive algorithm for its online case with a provable lower bound of 2 for any deterministic online algorithm. We verify our results through careful algorithmic analysis and validate their actual performance via a trace-based study based on a public open international mobile network dataset.
@article{10049541,author={Dai, Hao and Wu, Jiashu and Wang, Yang and Yen, Jerome and Zhang, Yong and Xu, Chengzhong},journal={IEEE Transactions on Services Computing},title={Cost-Efficient Sharing Algorithms for DNN Model Serving in Mobile Edge Networks},year={2023},volume={16},number={4},pages={2517-2531},doi={10.1109/TSC.2023.3247049},impactfactor={8.1},erank={SCI Q1},crank={CCF-A},dimensions={true},}
PackCache
PackCache: An Online Cost-Driven Data Caching Algorithm in the Cloud
@article{9833301,author={Wu, Jiashu and Dai, Hao and Wang, Yang and Zhang, Yong and Huang, Dong and Xu, Chengzhong},journal={IEEE Transactions on Computers},title={PackCache: An Online Cost-Driven Data Caching Algorithm in the Cloud},year={2023},volume={72},number={4},pages={1208-1214},doi={10.1109/TC.2022.3191969},dimensions={true},impactfactor={3.7},erank={SCI Q2},crank={CCF-A}}
GGA
Heterogeneous Domain Adaptation for IoT Intrusion Detection: A Geometric Graph Alignment Approach
@article{10026337,author={Wu, Jiashu and Dai, Hao and Wang, Yang and Ye, Kejiang and Xu, Chengzhong},journal={IEEE Internet of Things Journal},title={Heterogeneous Domain Adaptation for IoT Intrusion Detection: A Geometric Graph Alignment Approach},year={2023},volume={10},number={12},pages={10764-10777},doi={10.1109/JIOT.2023.3239872},impactfactor={10.6},erank={SCI Q1},crank={CCF-C},dimensions={true}}
2022
Coknight
Towards scalable and efficient Deep-RL in edge computing: A game-based partition approach
Hao
Dai, Jiashu
Wu, Yang
Wang, and
1 more author
Journal of Parallel and Distributed Computing, 13–19 jul 2022
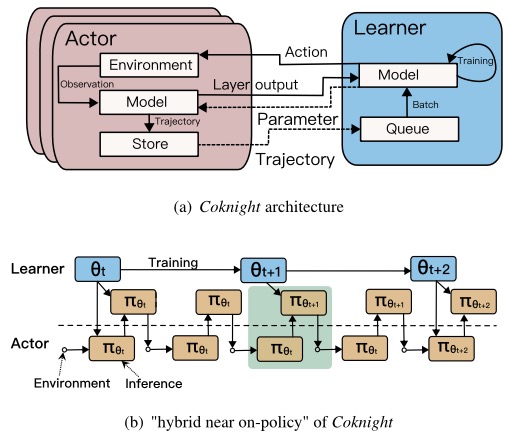
Currently, most edge-based Deep Reinforcement Learning (Deep-RL) applications have been deployed in the edge network, however, their mainstream studies are still short of adequate considerations on its limited compute and bandwidth resources. In this paper, we investigate the near on-policy of actions taking in distributed Deep-RL architecture, and propose a “hybrid near on-policy” Deep-RL framework, called Coknight, by leveraging a game-theory based DNN partition approach. We first formulate the partition problem into a variant of knapsack problem in device-edge setting, and then transform it into a potential game with a formal proof. Finally, we show the problem is NP-complete whereby an efficient distributed algorithm based on the potential game theory is developed from device perspective to achieve fast and dynamic partitioning. Coknight not only significantly improves the resource efficiency of the Deep-RL but also allows the inference to enforce the scalability of the actor policy. We prototype the framework with extensive experiments to validate our findings. The experimental results show that with the premise of a rapid convergence guarantee, Coknight, compared with Seed-RL, can reduce GPU utilization by 30% while providing large-scale scalability.
@article{DAI2022108,title={Towards scalable and efficient Deep-RL in edge computing: A game-based partition approach},journal={Journal of Parallel and Distributed Computing},volume={168},pages={108-119},year={2022},issn={0743-7315},doi={10.1016/j.jpdc.2022.06.006},url={https://www.sciencedirect.com/science/article/pii/S0743731522001411},author={Dai, Hao and Wu, Jiashu and Wang, Yang and Xu, Chengzhong},keywords={Mobile edge computing, Deep reinforcement learning, DNN partition, Game theory},dimensions={true},impactfactor={3.8},erank={SCI Q2},crank={CCF-B},}
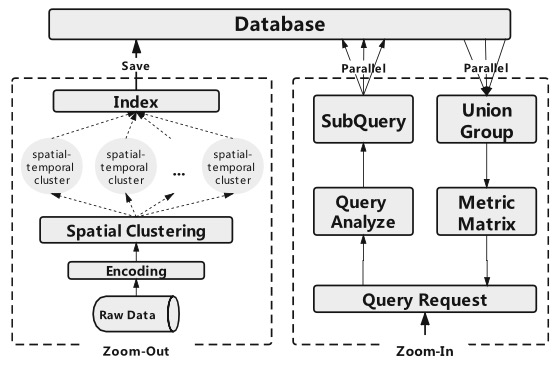
Ospery
Osprey: A Heterogeneous Search Framework for Spatial-Temporal Similarity
In this paper, a heterogeneous spatial-temporal similarity search framework is proposed, in which the datasets come from multiple different asynchronous data sources. Due to measuring error, data loss, and other factors, the similarity search based on single points along a trajectory usually cannot fulfill the accuracy requirements in our heterogeneous case. To address this issue, we introduce a concept of the spatial-temporal cluster of points, instead of single points, which can be identified for each target query. By following this concept, we further design a spectral clustering algorithm to construct the clusters in the pre-processing phase effectively. And the query processing is improved for the accuracy of the search by unifying multiple search metrics. To validate our idea, we also prototype a clustered online spatial-temporal similarity search system, "Osprey", to calculate in parallel the similarity of spatial-temporal sequences in the heterogeneous search on a distributed database. Our empirical study is conducted based on an open dataset, called "T-Drive", and a billion-scale dataset consisting of WiFi positioning records gathered from the urban metro system in Shenzhen, China. The experimental results show that the latency of our proposed system is less than 4s in most cases, and the accuracy is more than 70% when the similarity exceeds 0.5.
@article{10.1007/s00607-022-01075-4,author={Dai, Hao and Wang, Yang and Xu, Chengzhong},title={Osprey: A Heterogeneous Search Framework for Spatial-Temporal Similarity},year={2022},issue_date={Sep 2022},publisher={Springer-Verlag},address={Berlin, Heidelberg},volume={104},number={9},issn={0010-485X},url={https://doi.org/10.1007/s00607-022-01075-4},doi={10.1007/s00607-022-01075-4},journal={Computing},month=sep,pages={1949–1975},numpages={27},keywords={Spectral clustering, Spatial-temporal trajectory, 68P20 (Information storage and retrieval of data), Query processing, Heterogeneous similarity search, 68P10 (Searching and sorting)},impactfactor={3.7},erank={SCI Q2},}
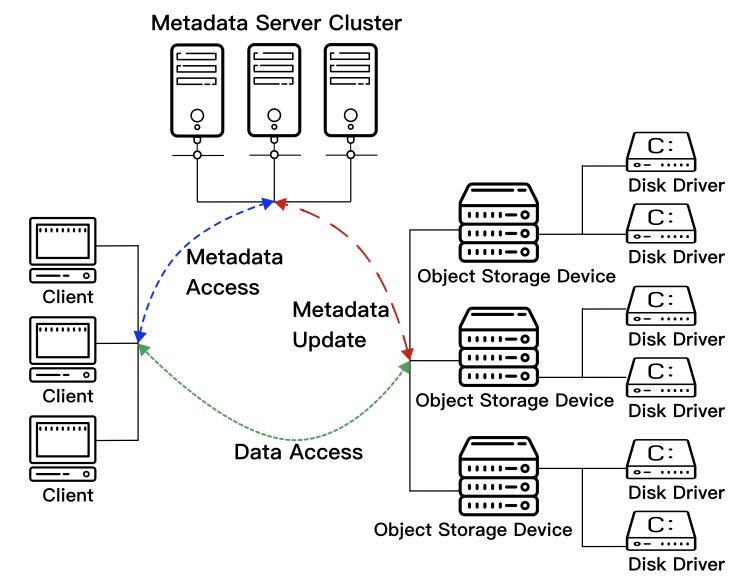
DFS
The State of the Art of Metadata Managements in Large-Scale Distributed File Systems — Scalability, Performance and Availability
Hao
Dai, Yang
Wang, Kenneth B.
Kent, and
2 more authors
IEEE Transactions on Parallel and Distributed Systems, Sep 2022
File system metadata is the data in charge of maintaining namespace, permission semantics and location of file data blocks. Operations on the metadata can account for up to 80% of total file system operations. As such, the performance of metadata services significantly impacts the overall performance of file systems. A large-scale distributed file system (DFS) is a storage system that is composed of multiple storage devices spreading across different sites to accommodate data files, and in most cases, to provide users with location independent access interfaces. Large-scale DFSs have been widely deployed as a substrate to a plethora of computing systems, and thus their metadata management efficiency is crucial to a massive number of applications, especially with the advent of the Big Data age, which poses tremendous pressure on underlying storage systems. This paper reports the state-of-the-art research on metadata services in large-scale distributed file systems, which is conducted from three indicative perspectives that are always used to characterize DFSs: high-scalability, high-performance, and high-availability, with special focus on their respective major challenges as well as their developed mainstream technologies. Additionally, the paper also identifies and analyzes several existing problems in the research, which could be used as a reference for related studies.
@article{9768784,author={Dai, Hao and Wang, Yang and Kent, Kenneth B. and Zeng, Lingfang and Xu, Chengzhong},journal={IEEE Transactions on Parallel and Distributed Systems},title={The State of the Art of Metadata Managements in Large-Scale Distributed File Systems — Scalability, Performance and Availability},year={2022},volume={33},number={12},pages={3850-3869},doi={10.1109/TPDS.2022.3170574},dimensions={true},impactfactor={5.3},erank={SCI Q1},crank={CCF-A},}
Deadlock
Deadlock Avoidance Algorithms for Recursion-Tree Modeled Requests in Parallel Executions
We present an extension of the banker’s algorithm to resolve deadlock for programs whose resource-request graph can be modeled as a recursion tree for parallel execution. Our algorithm implements the banker’s logic, with the key difference being that some properties of the tree are fully exploited to improve the resource utilization and safety check in deadlock avoidance. For an n -node tree modeled program making requests to m types of resources, our recursion-tree based algorithm can obtain a time complexity of O(mnloglogn) on average in safety check while reducing the conservativeness in resource utilization. We reap these benefits by proposing a concept of the resource critical tree and leverage it to localize the maximum claim associated with each node in the tree. To tackle the case when the tree model is not statically known, we relax the definition of a local maximum claim by sacrificing some resource utilization. With this trade-off, the algorithm can resolve the deadlock and achieve more efficient safety checks within time of O(mloglogn) . Our empirical studies on a two-dimensional integration problem on sparse grids show that the proposed algorithms can reduce resource utilization conservativeness and improve avoidance performance by minimizing the number of safety checks.
@article{9591378,author={Wang, Yang and Li, Min and Dai, Hao and Kent, Kenneth B. and Ye, Kejiang and Xu, Chengzhong},journal={IEEE Transactions on Computers},title={Deadlock Avoidance Algorithms for Recursion-Tree Modeled Requests in Parallel Executions},year={2022},volume={71},number={9},pages={2073-2087},doi={10.1109/TC.2021.3122843},dimensions={true},impactfactor={3.7},erank={SCI Q2},crank={CCF-A}}
2021
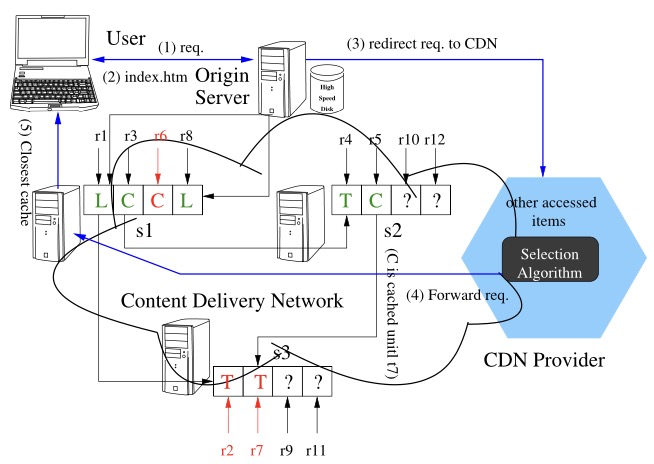
AC3
Cost-Driven Data Caching in Edge-Based Content Delivery Networks
Yang
Wang, Hao
Dai, Xinxin
Han, and
3 more authors
In this paper we study a data caching problem in edge-based content delivery network (CDN) where a data item is shared between service requests. Instead of improving the hit ratio with respect to limited capacity as in traditional case, we study the problem based on a semi-homogeneous (semi-homo) cost model in the edge-based CDN with monetary cost reduction as a goal. The cost model is semi-homo in the sense that all pairs of caching nodes have the same transfer cost, but each has its own caching cost rate. In particular, given a stream of requests R to a shared data item in the edge network, we present a shortest-path based optimal off-line caching algorithm that can minimize the total transfer and caching costs within O(mn) time ( m: the number of network nodes, n: the length of request stream) in a proactive fashion. While for the online case, by extending the anticipatory caching idea, we also propose a 2-competitive online reactive caching algorithm and show its tightness by giving a lower bound of the competitive ratio as 2−o(1) for any deterministic online algorithm. Finally, to combine the advantages of both algorithms and evaluate our findings, we also design a hybrid algorithm. Our trace-based empirical studies show that the proposed algorithms not only improve the previous results in both time complexity and competitive ratio, but also relax the cost model to semi-homogeneity, rendering the algorithms more practical in reality. We provably achieve these results with our deep insights into the problem and careful analysis of the solutions, together with a prototype framework.
@article{9525245,author={Wang, Yang and Dai, Hao and Han, Xinxin and Wang, Pengfei and Zhang, Yong and Xu, Chengzhong},journal={IEEE Transactions on Mobile Computing},title={Cost-Driven Data Caching in Edge-Based Content Delivery Networks},year={2021},volume={22},number={3},pages={1384-1400},doi={10.1109/TMC.2021.3108150},dimensions={true},impactfactor={7.9},erank={SCI Q1},crank={CCF-A},}
2020
Themis
Predicting and reining in application-level slowdown on spatial multitasking GPUs
Mengze
Wei, Wenyi
Zhao, Quan
Chen, and
5 more authors
Journal of Parallel and Distributed Computing, Sep 2020
Predicting performance degradation of a GPU application at co-location on a spatial multitasking GPU without prior application knowledge is essential in public Clouds. Prior work mainly targets CPU co-location, and is inaccurate and/or inefficient for predicting performance of applications at co-location on spatial multitasking GPUs. Our investigation shows that hardware event statistics caused by co-located applications strongly correlate with their slowdowns. Based on this observation, we present Themis with a kernel slowdown model (Themis-KSM), which performs precise and efficient online application slowdown prediction without prior application knowledge. The kernel slowdown model is trained offline. When new applications co-run, Themis-KSM collects event statistics and predicts their slowdowns simultaneously. In addition, we also propose a two-stage slowdown prediction mechanism (Themis-TSP) for real-system GPUs without any hardware modification. Our evaluation shows that Themis has negligible runtime overhead, and both Themis-KSM and Themis-TSP can precisely predict application-level slowdown with prediction error smaller than 9.5% and 12.8%, respectively. Based on Themis, we also implement an SM allocation engine to rein in application slowdown at co-location. Case studies show that the engine successfully enforces fair sharing and QoS.
@article{WEI202099,title={Predicting and reining in application-level slowdown on spatial multitasking GPUs},journal={Journal of Parallel and Distributed Computing},volume={141},pages={99-114},year={2020},issn={0743-7315},doi={https://doi.org/10.1016/j.jpdc.2020.03.009},url={https://www.sciencedirect.com/science/article/pii/S0743731519307361},author={Wei, Mengze and Zhao, Wenyi and Chen, Quan and Dai, Hao and Leng, Jingwen and Li, Chao and Zheng, Wenli and Guo, Minyi},keywords={Spatial Multitasking GPU, Sharing GPU, Co-location, Slowdown prediction, Performance prediction},dimensions={true},impactfactor={3.8},erank={SCI Q2},crank={CCF-B}}